| open_sora | ||
| scripts | ||
| tests | ||
| .gitignore | ||
| .isort.cfg | ||
| .pre-commit-config.yaml | ||
| benchmark.py | ||
| download.py | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
| sample.py | ||
| setup.py | ||
| train.py | ||
| version.txt | ||
🎥 Open-Sora


📎 Table of Contents
Latest News
- [2024/03] Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million
📍 Overview
Open-Sora is an open-source project that provides a high-performance implementation of the development pipeline that Sora might use powered by Colossal-AI, including:
- Provides a complete Sora reproduction architecture solution, including the whole process from data processing to training and deployment.
- Supports dynamic resolution, training can directly train any resolution of the video, without scaling.
- Supports multiple model structures. Since the actual model structure of Sora is unknown, we implement three common multimodal model structures such as adaLN-zero, cross attention, and in-context conditioning (token concat).
- Supports multiple video compression methods. Users can choose to use original video, VQVAE (video native model), or SD-VAE (image native model) for training.
- Supports multiple parallel training optimizations. Including the AI large model system optimization capability compatible with Colossal-AI, and hybrid sequence parallelism with Ulysses and FastSeq.
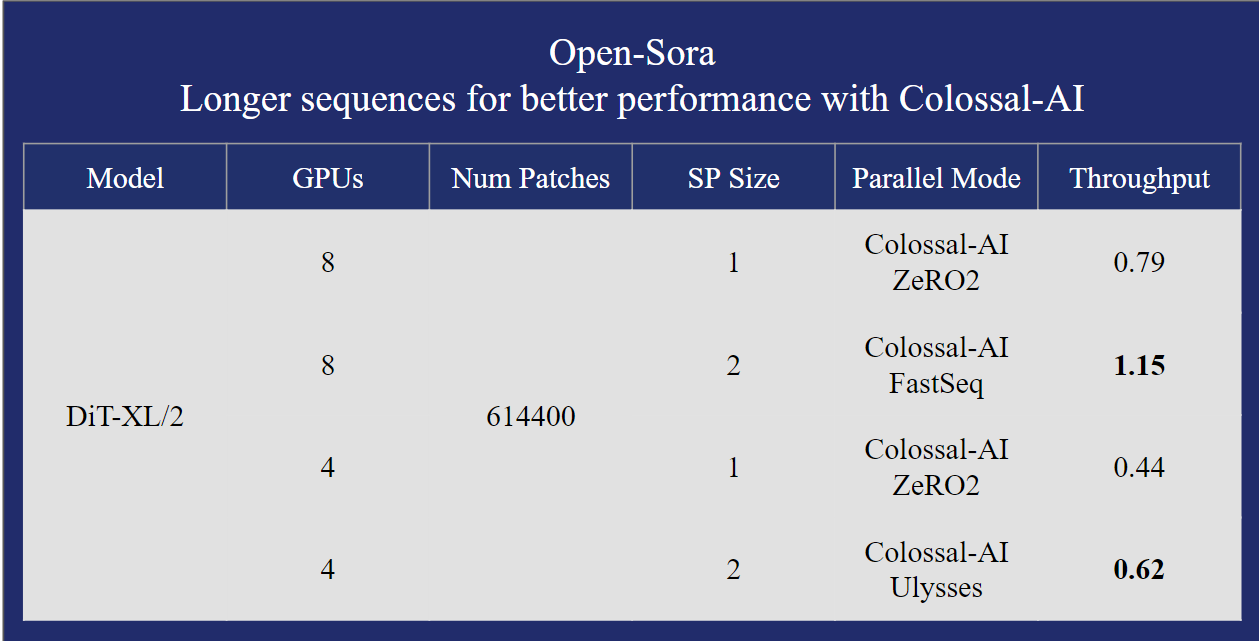
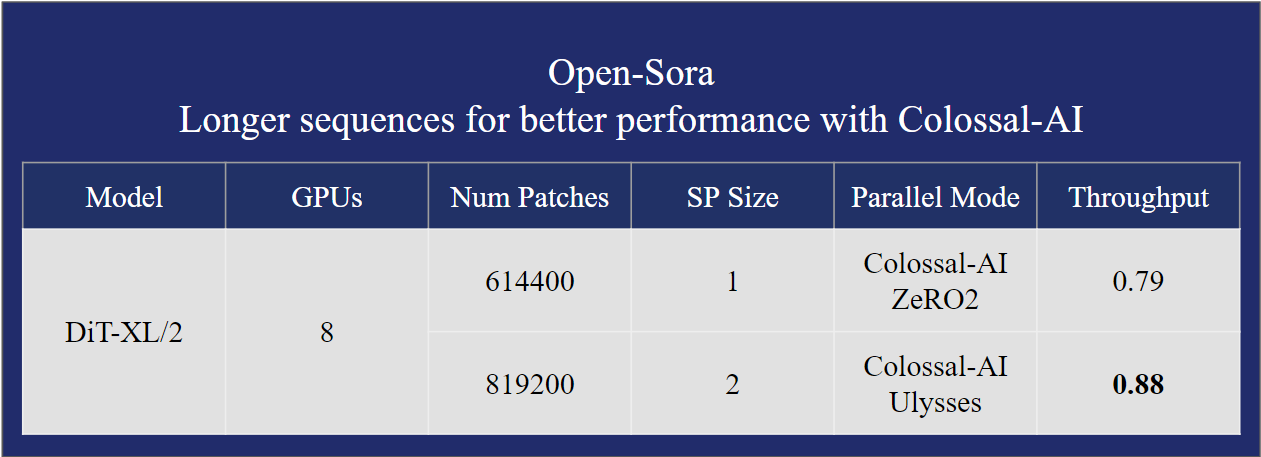
📂 Dataset Preparation
Use MSR-VTT
We use MSR-VTT dataset, which is a large-scale video description dataset. Users should preprocess the raw videos before training the model. You can use the following scripts to perform data processing.
# Step 1: download the dataset to ./dataset/MSRVTT
bash scripts/data/download_msr_vtt_dataset.sh
# Step 2: collate the video and annotations
python scripts/data/collate_msr_vtt_dataset.py -d ./dataset/MSRVTT/ -o ./dataset/MSRVTT-collated
# Step 3: perform data processing
# NOTE: each script could several minutes so we apply the script to the dataset split individually
python scripts/data/preprocess_data.py -c ./dataset/MSRVTT-collated/train/annotations.json -v ./dataset/MSRVTT-collated/train/videos -o ./dataset/MSRVTT-processed/train
python scripts/data/preprocess_data.py -c ./dataset/MSRVTT-collated/val/annotations.json -v ./dataset/MSRVTT-collated/val/videos -o ./dataset/MSRVTT-processed/val
python scripts/data/preprocess_data.py -c ./dataset/MSRVTT-collated/test/annotations.json -v ./dataset/MSRVTT-collated/test/videos -o ./dataset/MSRVTT-processed/test
After completing these steps, you should have a processed MSR-VTT dataset in ./dataset/MSRVTT-processed.
Use Customized Datasets
You can also use other datasets and transform the dataset to the required format. You should prepare a captions file and a video directory. The captions file should be a JSON file or a JSONL file. The video directory should contain all the videos.
Here is an example of the captions file:
[
{
"file": "video0.mp4",
"captions": ["a girl is throwing away folded clothes", "a girl throwing cloths around"]
},
{
"file": "video1.mp4",
"captions": ["a comparison of two opposing team football athletes"]
}
]
Here is an example of the video directory:
.
├── video0.mp4
├── video1.mp4
└── ...
Each video may have multiple captions. So the outputs are video-caption pairs. E.g., If the first video has two captions, then the output will be two video-caption pairs.
We use VQ-VAE to quantize the video frames. And we use CLIP to extract the text features.
The output is an arrow dataset, which contains the following columns: "video_file", "video_latent_states", "text_latent_states". The dimension of "video_latent_states" is (T, H, W), and the dimension of "text_latent_states" is (S, D).
Then you can run the data processing script with the command below:
python preprocess_data.py -c /path/to/captions.json -v /path/to/video_dir -o /path/to/output_dir
Note that this script needs to be run on a machine with a GPU. To avoid CUDA OOM, we filter out the videos that are too long.
🚀 Get Started
In this section, we will guide how to run training and inference. Before that, make sure you installed the dependencies with the command below.
pip install -r requirements.txt
Training
You can invoke the training via the command below.
bash ./scripts/train.sh
You can also modify the arguments in train.sh for your own need.
Inference
We've provided a script to perform inference, allowing you to generate videos from the trained model. You can invoke the inference via the command below.
python sample.py -m "DiT/XL-2" --text "a person is walking on the street" --ckpt /path/to/checkpoint --height 256 --width 256 --fps 10 --sec 5 --disable-cfg
This will generate a "sample.mp4" file in the current directory.
For more command line options, you can use the following command to check the help message.
python sample.py -h
🪄 Acknowledgement
During the development of the project, we learned a lot from the following information: